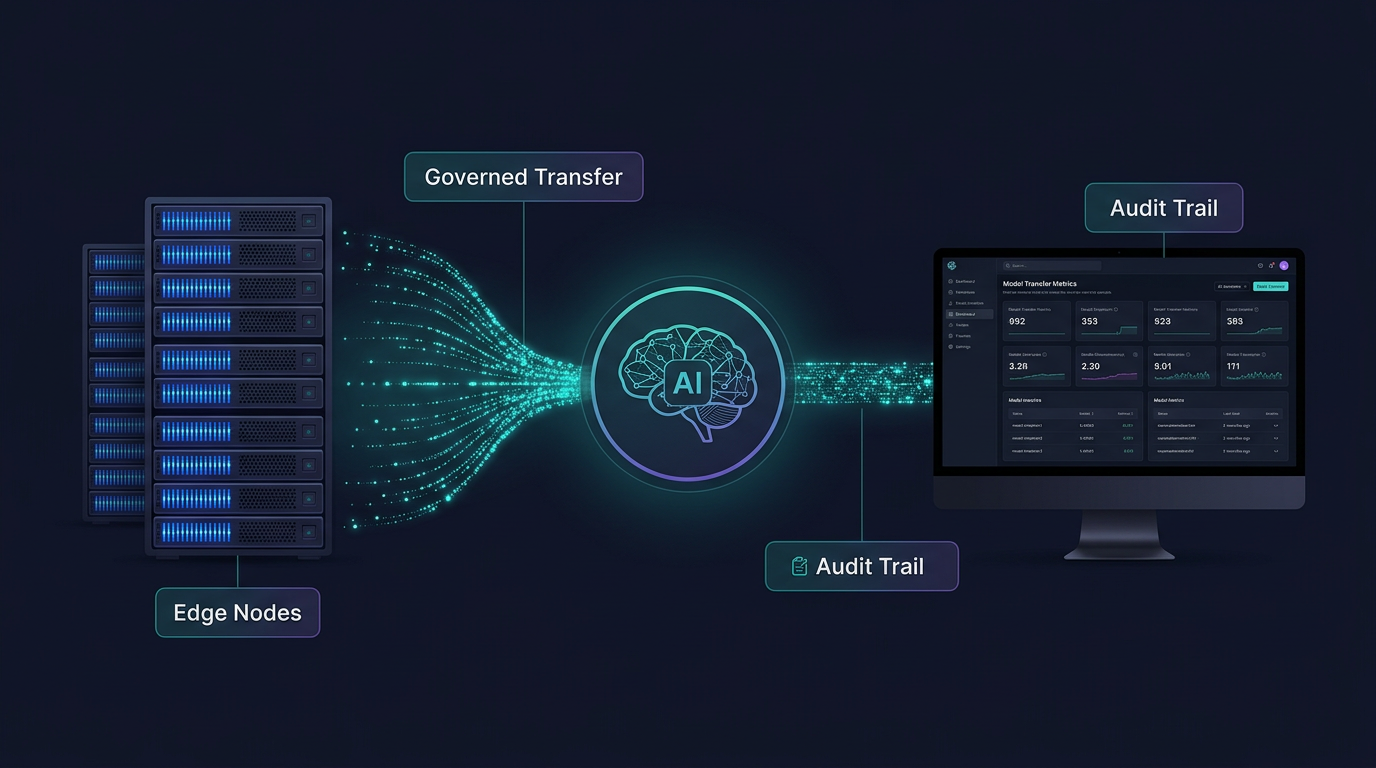
Between Systems: Keep Your AI Workflows Fed with Files and Objects via Streaming and Caching
Model delivery, training-set replication, fine-tune pushes, and inference-cache sync move quickly while protection and audit stay in the path.
- Large model bundles and datasets move across distance
- Training and fine-tune artifacts reach approved systems
- Federated learning workflows can respect sovereignty zones
- Benchmark proof is available for performance review